存錢不如炒股?653家上市公司股息率超3%,跑贏低利率,煤炭銀行石油居前三
- 编辑:賓朋滿座網 - 67存錢不如炒股?653家上市公司股息率超3%,跑贏低利率,煤炭銀行石油居前三
本文節選自:
郭旺, 楊雨森, 吳華瑞, 朱華吉, 繆禕晟, 顧靜秋. 農業大模型:關鍵技術、應用分析與發展方向[J]. (中英文), 2024, 6(2): 1-13.
GUO Wang, YANG Yusen, WU Huarui, ZHU Huaji, MIAO Yisheng, GU Jingqiu. Big Models in Agriculture: Key Technologies, Application and Future Directions[J]. Smart Agriculture, 2024, 6(2): 1-13.⠀
農業大模型關鍵技術與特性
大模型依賴於諸多技術支撐,也具有區別於其他人工智能模型的特性。Transformer架構是當今眾多大模型的基礎,使大模型能夠有效處理大規模的數據並擴展模型規模,擴展定理則指導大模型進行有限預算的最優開發,大規模的自監督學習使模型在無需人工監督的情況下擴展訓練規模來提升能力。同時,大模型中新產生的湧現能力(Emergent abilities),是其區別於其他小規模模型的重要特征。
1. Transformer模型的產生與核心原理
Transformer架構的設計核心是一種簡單高效的自注意力(Self-attention)機製,通過計算序列內元素間的相互關注度分數,為各元素賦予差異化的重要性權重。這一設計使得模型能夠在處理序列數據時,動態地集中處理序列中的關鍵信息,並能夠覆蓋序列中任意位置的數據元素,有效捕捉長程依賴關係。這種機製使得模型能夠方便地擴展,不會因此在模型推理時丟失細節。此外,Transformer模型的架構允許並行化計算,模型在參數規模較大時訓練效率有了顯著提升。這些特性促使其在大模型領域具有廣泛應用。
Transformer推動了自然語言處理領域的一係列重大進展。BERT(Bidirectional Encoder Representations from Transformers)、GPT等基於Transformer架構的預訓練語言模型相繼產生,並在文本翻譯等子領域展示出卓越的性能。GPT使用了Transformer中的解碼器設計,允許文本正向輸入,並通過預測文本序列中的下一詞來進行訓練,使模型能夠理解並生成連貫的文本內容。BERT則使用雙向Transformer編碼器架構,能夠考慮到給定單詞在上下文中的前後信息,實現同時從正向和反向與對文本的深入理解,顯著提升了模型對語義的把握能力。同時,BERT通過在掩碼語言建模(Masked Language Modeling)與下一句預測(Next Sentence Prediction),學習到複雜的語境關係。隨著模型的進一步擴大,例如GPT-3、LLaMa(Large Language Model Meta AI)等語言大模型的開發,將模型能力推升至新的高度。同時,Transformer架構的影響也擴展到了其他的人工智能子領域,如計算機視覺領域的代表模型ViT(Vision Transformer),通過將圖像分割成多個小塊並應用Transformer架構處理,打破了傳統依賴卷積神經網絡(Convolutional Neural Networks, CNNs)的圖像處理範式。進一步地,Caron等將ViT與自監督學習結合,提出了DINO(Self-distillation with No Labels)框架,在自監督條件下也能學習到圖像中的深層語義特征,為構造視覺大模型奠定了一定的理論基礎。
2. 大模型的擴展定理
Transformer架構允許模型進行大規模的堆疊,而對模型規模、數據規模與計算量的擴展,可以大幅提高模型能力。尤其在語言大模型領域,開展了一些對擴展的定量研究。語言大模型發展出兩個代表性的法則:KM(Kaplan-McCandlish)法則與Chinchilla法則。KM法則是通過擬合神經語言模型的性能在不同模型規模(N)、數據集規模(D),以及訓練計算量(C)三種變量的表現提出了一種性能隨這三種要素擴展而提升的定量描述;Chinchilla法則提出了另一種形式來指導語言大模型進行最優計算量的訓練,認為模型大小與數據量應以同比增加來在一定預算下取得最優模型。KM法則可以表示為公式(1)~公式(3),Chinchilla法則表示為公式(4)~公式(6)。
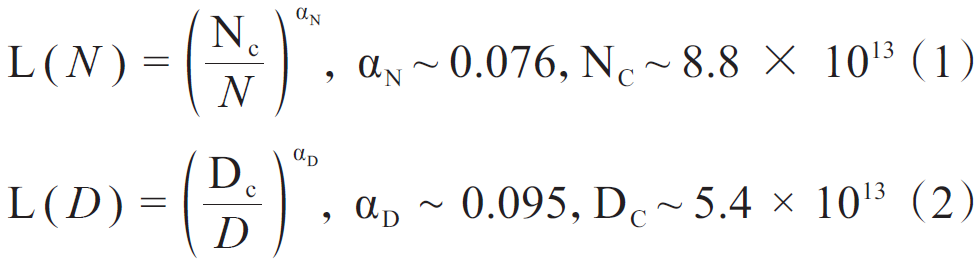
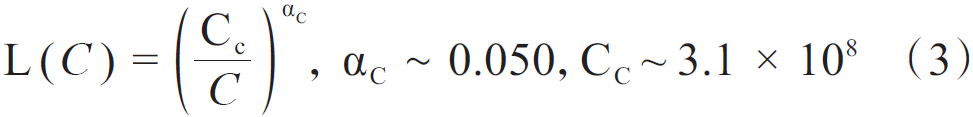
式中:L(ⷩ為nats表示下的交叉熵損失。
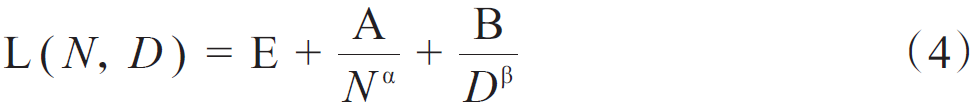
式中:E=1.69,A=406.4,B=410.7,0.34,0.28。在C≈6ND的條件下,將計算預算分配給模型規模與數據量的最優解,為公式(5)和公式(6)。
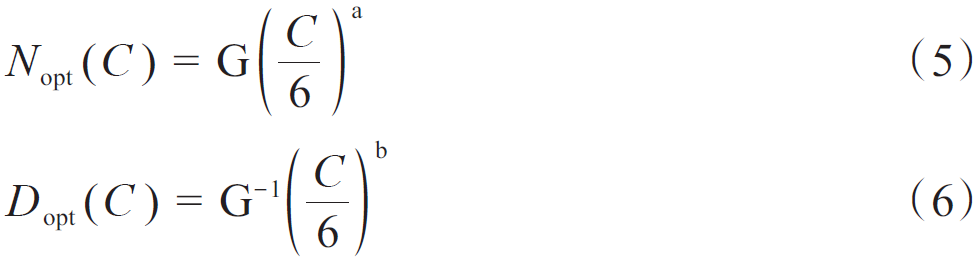 式中:
式中: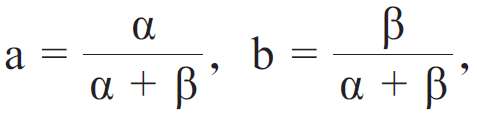
G為基於A、B、 與 舧š„擴展係數。
3. 大規模自監督學習
大模型的能力依賴於大規模的訓練。早期的深度學習模型基於監督訓練,依賴於對數據的人工標注。這種方式耗時耗力,限製了模型的訓練規模。相對地,自監督學習的核心思想是利用數據本身自動化地產生對應的監督信號,使模型能夠在未經人工標注的數據上,學習到有用的特征,進行自我監督。通過減少或避免對人工的依賴,使得在更廣泛、更大規模的數據集上進行訓練成為可能。
在大模型領域,自監督學習主要采用生成式學習與對比學習兩種策略。生成式學習,也稱預測學習,旨在通過模型生成與訓練數據相似的數據,深入挖掘數據的內在結構及生成過程的潛在因素。生成式學習在語言模型中應用廣泛,如BERT模型通過掩碼語言建模與下一句預測進行訓練,前者旨在預測文本中挖空的詞匯,後者則是從候選句子中挑選出最合適作為文本下文的句子。對比學習則廣泛地應用到計算機視覺領域中,如SimCLR(Simple Framework for Contrastive Learning of Visual Representations)架構,將同一批圖片采用不同方式增強後進行編碼,最大化來自相同圖片的編碼的相似性,以此學習對圖片的特征表示。
同時,進行大規模自監督學習的可擴展性訓練技術也至關重要,可以包括如使用3D並行技術(數據並行、流水線並行、張量並行等),將計算分散到多個GPU上進行訓練,或使用零冗餘優化器(Zero Redundancy Optimizer, ZeRO)技術,解決數據在多GPU部署後的冗餘問題,以及采用混合精度訓練,減少計算量與數據傳輸開銷。這些技術結合計算機硬件的持續進步,為大模型的規模擴展和訓練效率提供了堅實的算力支持。
4.⠥䧦补ž‹通用能力與適應微調
經過預訓練,大模型具有解決廣泛任務的通用能力。通過一定的提示(Prompts),大模型能夠執行不同的具體任務。如ChatGPT可基於語言等提示,執行如文本翻譯、開放領域問答、文本摘要、文本生成等多種自然語言處理上的具體任務;Meta公司開發的SAM(Segment Anything Model)允許使用文本提示與可視化的分割範圍提示,對照片中的具體物體進行實例分割。
大模型可以通過微調適配到特定的目標上。如在語言大模型上可以進行指令微調(Instruction tuning)與對齊微調(Alignment tuning)兩種微調方法。前者通過構建人工參與的格式化的指令,包含任務描述、輸入輸出以及可選的少量示例等,監督大模型對特定的工作進行調節,提升其完成具體目標的能力;後者則著重於將人類的價值取向與偏好等對齊於語言大模型,防止其生成有害的、虛假的、帶有偏見的等不符合人類期望的內容,一般采用基於人類反饋的強化學習(Reinforcement Learning from Human Feedback, RLHF)方法,通過收集的人類反饋進行訓練獎勵,有監督地調節模型。視覺大模型亦可通過微調工作,來提高模型在特定任務,如開放世界物體檢測中的性能,也可提高模型的某種能力,如視覺定位(Visual Grounding)等。
對模型進行全參數微調需要大量計算資源。而對模型添加少量額外結構,就能使模型在僅調節這些結構後快速適應下遊任務。這種參數高效微調的方法包括適配器微調(Adapter Tuning)、前綴微調(Prefix tuning)、低秩適應(Low-Rank Adaption, LoRA)微調以及提示微調(Prompt tuning)等。適應器微調通過在模型的多頭注意力層與前饋層之間插入小型的神經網絡模塊來實現;前綴微調則是向模型的輸入添加一係列固定的向量(即前綴)來引導模型輸出;而LoRA微調通過在Transformer層中添加低秩矩陣來模擬模型內部較低的本征維度,從而使用少量參數進行快速學習。此外,提示微調則通過自動調整添加到輸入上的提示模板來激發模型在特定任務上的性能。這些方法的出現顯著降低了微調的計算量,促進了大模型在多個領域的推廣。
5. 湧現能力
語言大模型與一般預訓練語言模型的主要區別之一是湧現出在較小模型上難以出現的能力,即湧現能力。將模型的規模提升到一定程度,其能夠展現出解決複雜的問題的新能力。其中有三種典型能力:上下文學習(In-Context Learning)、指令遵循,以及逐步推理。上下文學習是指模型能夠按照一定的自然語言指令以及任務演示,對測試樣例進行補全來生成答案,不需要對模型參數進行更新。指令遵循是指模型在混合多任務數據集上進行微調後,在格式相同但未曾見過的任務中具有良好表現,即便沒有顯式的示例依然可以遵循新的命令。逐步推理則強調語言大模型可以解決涉及多個推理步驟的複雜任務,通過思維鏈(Chain of Thought)等方式生成中間的推理步驟,最後生成最終的答案。
(轉自:智慧農業期刊)